N1904-TF
Text-Fabric dataset of the Greek New Testament, based on the Nestle 1904 (7th printing) edition.
About this datasetTranscription
Featureset
Optional features
Viewtypes
Textformats
Syntaxtrees
Tutorial
Latest release
Nestle 1904 GNT - Feature: punctuation
| Feature group | Feature type | Data type | Available for node types | Used by viewtypes |
|---|---|---|---|---|
Orthograpic |
Node |
String |
word subphrase phrase |
syntax-view wg-view |
Feature description
This feature contains the punctuation character found after a word. If no punctuation, the feature value is empty.
This feature is also populated for phrase or subphrase, but only if they consist of just one word node.
Feature values
For word nodes (used in syntax-view and wg-view):
| Value | Description | Unicode codepoint | Frequency |
|---|---|---|---|
, |
Comma | , |
9462 |
. |
Full Stop | . |
5717 |
· |
Midle Dot | · |
2359 |
; |
Semicolon | ; |
971 |
| <empty> | No punctuation | 119270 |
For phrase nodes (used in syntax-view):
| Value | Description | Unicode codepoint | Frequency |
|---|---|---|---|
, |
Comma | , |
3903 |
. |
Full Stop | . |
2731 |
· |
Midle Dot | · |
1189 |
; |
Semicolon | ; |
589 |
| <empty> | No punctuation | 60595 |
For subphrase nodes (used in syntax-view):
| Value | Description | Unicode codepoint | Frequency |
|---|---|---|---|
, |
Comma | , |
9462 |
. |
Full Stop | . |
5717 |
· |
Midle Dot | · |
2359 |
; |
Semicolon | ; |
971 |
| <empty> | No punctuation | 106081 |
Notes
This feature enables easy testing for the presence of punctuation following a word. To retrieve all word nodes without trailing punctuation, use the following snippet:
Query = '''
word
punctuation#
'''
Results = A.search(Query)
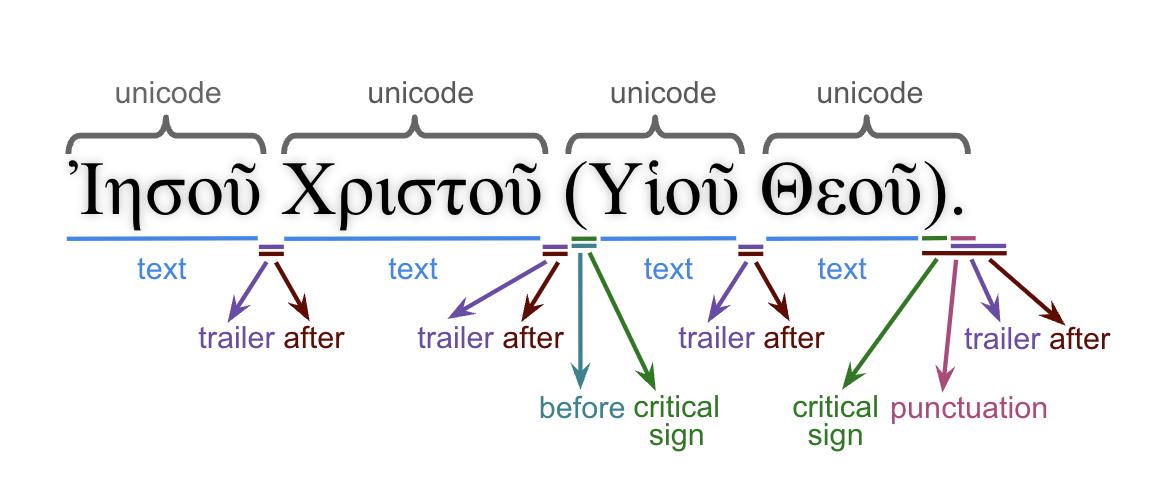
The following image shows the features describing the material found after a word.

The following set of features describe the full surface text:
- after: All material found after a word (including critical signs).
- before: All material found before a word.
- criticalsign: Text-critical signs.
- normalized: Normalized Greek text.
- punctuation (this feature): Punctuations found after a word.
- text: Word without punctuations and text-critical signs.
- trailer: All material found after a word (excluding critical signs).
- translit: Transliteration of the word surface texts.
- unaccent: Word without accents and diacritical markers.
- unicode: Unicode presentation including all material before and after word.
The following image shows the relation between these features.
The following text-formating options are defined in this dataset using this feature:
A.showFormats()
format level template
lex-orig-plain word {lemma}{trailer}
lex-translit-plain word {lextranslit}{trailer}
text-orig-full word {before}{text}{after}
text-orig-plain word {text}{trailer}
text-translit-plain word {translit}{trailer}
text-unaccent-plain word {unaccent}{trailer}
Source description
Calculated from the from XML attribute after of tag w (word).