N1904-TF
Text-Fabric dataset of the Greek New Testament, based on the Nestle 1904 (7th printing) edition.
About this datasetTranscription
Featureset
Optional features
Viewtypes
Textformats
Syntaxtrees
Tutorial
Latest release
Nestle 1904 GNT - Textformats
Text-Fabric’s data design allows for flexible representation of the corpus text but requires at least one text format to be specified as its default (in this dataset: text-orig-full). During the creation of the dataset, additional formats relevant to this corpus were defined, which are basically based on a subset of the following surface text-related features:
- after: All material found after a word (including text-critical signs).
- before: All material found before a word.
- criticalsign: Text-critical signs.
- normalized: Normalized Greek text.
- punctuation: Punctuations found after a word.
- text: Word without punctuations and text-critical signs.
- trailer: All material found after a word (excluding text-critical signs).
- translit: Transliteration of the word surface texts.
- unaccent: Word without accents and diacritical markers.
- unicode: Unicode presentation including all material before and after word.
The relation between these features in relation to the surface text is shown in the following image.
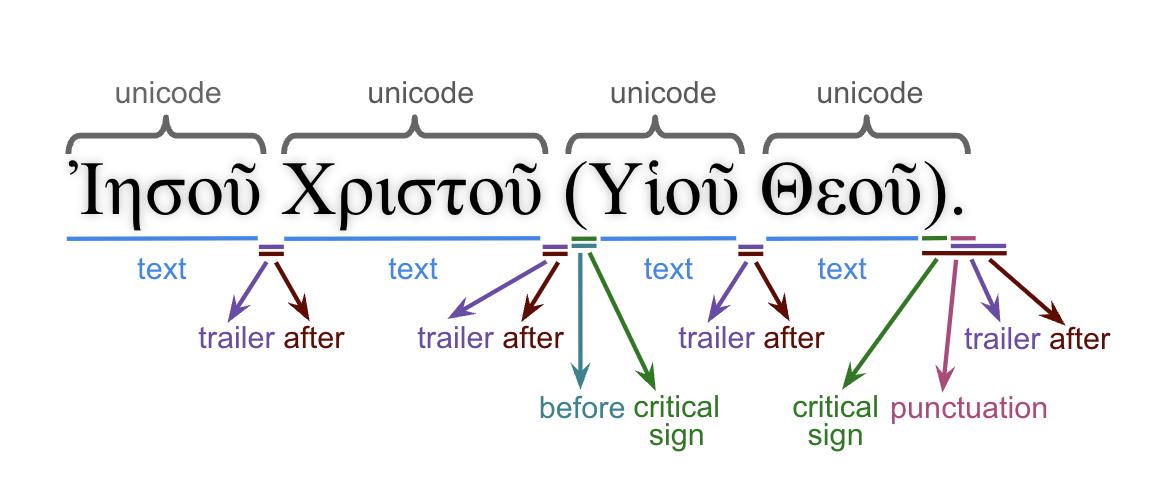
Naming schema for text formating
The text formats in this Text-Fabric database are identified by unique names that reflect their actual formats. These names follow a structured naming schema, consisting of a string of keywords separated by hyphens (-).
`what`-`how`-`fullness`
In our database the following keywords are used:
| keyword | value | meaning |
|---|---|---|
| what | text | words as they belong to the text |
| what | lex | lexemes of the words |
| how | orig | the original Greek script (all Unicode) |
| how | unaccent | the original Greek script without accents |
| how | translit | transliteration into latin alphabeth |
| fullness | full | complete text with text-critical markers |
| fullness | plain | complete text without text-critical markers |
Not all possible combinations are defined or relevant. The following text-formatting options are defined:
| Format | Usage | Template |
|---|---|---|
| lex-orig-plain | Lexemes of the Greek surface text | {lemma}{trailer} |
| lex-translit-plain | Transliteration of the lexemes of the Greek surface text | {lemmatranslit}{trailer} |
| text-orig-full (default) | The Greek surface text in unicode including text-critical markers | {before}{text}{after} |
| text-orig-plain | The Greek surface text in unicode | {text}{trailer} |
| text-translit-plain | Transliteration of the Greek surface text | {translit}{trailer} |
| text-unaccent-plain | The Greek surface text in unicode without accents | {unaccent}{trailer} |
Each text format is implemented as a template that maps the format to individual features. This mapping can be easily checked using the following command: A.showFormats().
Example
This example illustrates how the different formats in this dataset affect the presentation of Mark 1:1.
# note: node 383782 is of type 'verse' and associated to Mark 1:1
for formats in T.formats:
print(f'fmt={formats}\t: {T.text(383782,formats)}')
fmt=lex-orig-plain : ἀρχή ὁ εὐαγγέλιον Ἰησοῦς Χριστός υἱός θεός.
fmt=lex-translit-plain : arkhe o euaggelion Iesous Khristos uios theos.
fmt=text-orig-full : Ἀρχὴ τοῦ εὐαγγελίου Ἰησοῦ Χριστοῦ (Υἱοῦ Θεοῦ).
fmt=text-orig-plain : Ἀρχὴ τοῦ εὐαγγελίου Ἰησοῦ Χριστοῦ Υἱοῦ Θεοῦ.
fmt=text-translit-plain : Arkhe tou euaggeliou Iesou Khristou Uiou Theou.
fmt=text-unaccent-plain : Αρχη του ευαγγελιου Ιησου Χριστου Υιου Θεου.
Character encoding
All Greek text in this Text-Fabric dataset is encoded in Unicode. However, there are specific aspects that may require attention when querying, particularly those involving polytonic accents and “pseudo-characters” like the iota subscript. For a detailed discussion on character encoding, please refer to the documentation here.