N1904-TF
Text-Fabric dataset of the Greek New Testament, based on the Nestle 1904 (7th printing) edition.
About this datasetTranscription
Featureset
Optional features
Viewtypes
Textformats
Syntaxtrees
Tutorial
Latest release
Nestle 1904 GNT - Feature: before
| Feature group | Feature type | Data type | Available for node types | Used by viewtypes |
|---|---|---|---|---|
Textcritical |
Node |
String |
word subphrase phrase |
syntax-view wg-view |
Feature description
The before feature includes all material found before a word in the surface text which are or text-critical nature.
This feature is also populated for phrase or subphrase, but only if they consist of just one word node.
Feature values
For word nodes (used in syntax-view and wg-view):
| Value | Description | Unicode codepoint | Frequency |
|---|---|---|---|
— |
Em Dash | — |
16 |
( |
Left Parenthesis | ( |
10 |
[[ |
Left Square Bracket (2x) | [ (2x) |
7 |
[ |
Left Square Bracket | [ |
1 |
For subphrase nodes (used in syntax-view):
| Value | Description | Unicode codepoint | Frequency |
|---|---|---|---|
— |
Em Dash | — |
16 |
( |
Left Parenthesis | ( |
10 |
[[ |
Left Square Bracket (2x) | [ (2x) |
7 |
[ |
Left Square Bracket | [ |
1 |
For phrase nodes (used in syntax-view):
| Value | Description | Unicode codepoint | Frequency |
|---|---|---|---|
— |
Em Dash | — |
8 |
( |
Left Parenthesis | ( |
6 |
[[ |
Left Square Bracket (2x) | [ (2x) |
2 |
Notes
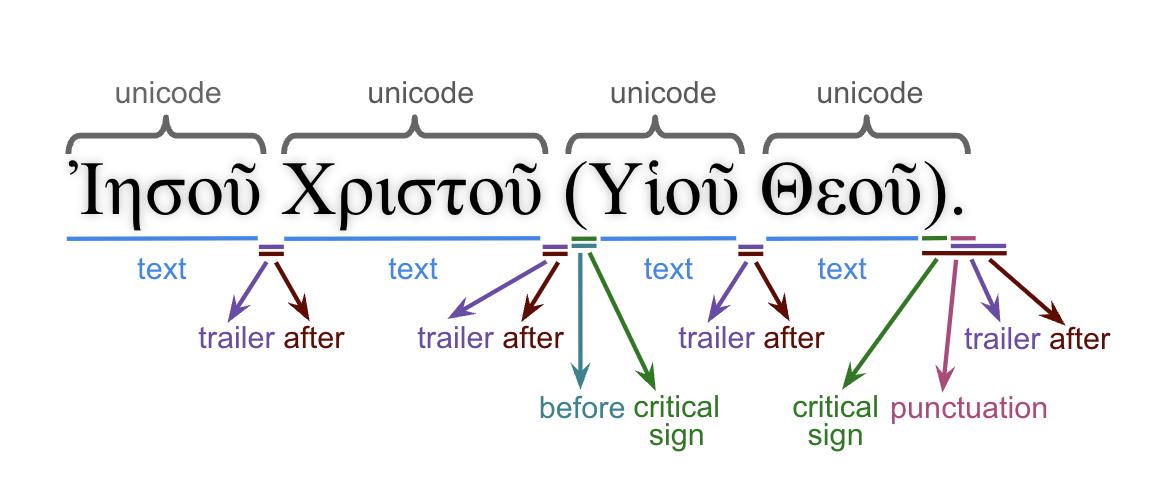
The following features describe the full surface text:
- after: All material found after a word (including critical signs).
- before (this feature): All material found before a word.
- criticalsign: Text-critical signs.
- normalized: Normalized Greek text.
- punctuation: Punctuations found after a word.
- text: Word without punctuations and text-critical signs.
- trailer: All material found after a word (excluding text-critical signs).
- translit: Transliteration of the word surface texts.
- unaccent: Word without accents and diacritical markers.
- unicode: Unicode presentation including all material before and after word.
The following image shows the relation between these features.
The following text-formating options are defined in this dataset using this feature:
A.showFormats()
format level template
lex-orig-plain word {lemma}{trailer}
lex-translit-plain word {lextranslit}{trailer}
text-orig-full word {before}{text}{after}
text-orig-plain word {text}{trailer}
text-translit-plain word {translit}{trailer}
text-unaccent-plain word {unaccent}{trailer}
Source description
The before feature is determined from the value of the XML tag w (word).