N1904-TF
Text-Fabric dataset of the Greek New Testament, based on the Nestle 1904 (7th printing) edition.
About this datasetTranscription
Featureset
Optional features
Viewtypes
Textformats
Syntaxtrees
Tutorial
Latest release
Nestle 1904 GNT - Syntaxtrees
This Nestle 1904 Text-Fabric dataset allows for the rendering of syntax trees following a constituency grammar, which describes sentences in terms of its constituent parts. These constituents are groups of words that function as a single unit (or abstraction) within a hierarchical structure. This approach emphasizes the grouping of words into phrases and how these phrases function together to create meaning. It is particularly useful for capturing nested structures like subordinate clauses. This use of constituency grammar allows also for querying complex nested sentence structures. It allows linguists, language learners, and researchers to analyzing the sentence’s syntax, identifying grammatical patterns, and understanding how words function within the sentence.
The relation between the constituent parts can be depicted in a syntax tree that functions as a graphical representation of the syntactic structure of a sentence. This structure is a hierarchical tree-like formation illustrating how different words in a sentence are grammatically connected to each other. In a syntax tree, each word (or morpheme) is represented as a node, and the relationships between words are depicted as branches or edges connecting these nodes. The tree starts with the main clause or the root node and branches out to represent subordinate clauses, phrases, and individual words. The tree structure reflects the hierarchical arrangement of grammatical elements within the sentence. The syntax tree provides valuable insights into the sentence’s grammatical structure, including the roles of nouns, verbs, adjectives, prepositions, conjunctions, and other parts of speech.
Theoretic example
The following image provides a basic representation of a syntax tree for the Greek text of John 1:1 based on a constituency grammar.

This syntax tree representation of the data of John 1:1 contains the indication of the sentence (root indicated with the capital S=Start), clauses that are separated by the conjunction καί (branches), and words (leaves). The labels indicate s as the subject, vc as the copulative verb (or linking verb), and p as the predicate. The diagram was created using the syntax tree generator developed by Miles Shang.
Creation of syntax trees
This Text-Fabric dataset is based upon the MACULA Greek treebank. This treebank was initially generated using an automatic parser that used machine-readable Greek grammar using the Nestle 1904 text with Urik Peterson’s morphology, which was then manually reviewed and edited. This process is described in this publication. The resulting treebank is further documented in Randall Tan and Andi Wu, Documentation for the MACULA Greek Treebank for the Nestle 1904 Greek New Testament (2022). A PDF version is available here.
This database implementation
This database has implemented different ways to display the syntaxtrees due to a partial data duplication using dedicated node types that associated with each of these syntaxtree types. The differences between the tree types are demonstrated in the following Jupyter Notebook and described below.
Syntaxtree using the syntax-view
The default way of presenting a syntax tree in this datatase is to mimicks the BHSA. That includes the use of nodes like clauses and phrases. This version of the syntaxtree is called syntax-view. By default, the command A.show() will provide syntaxtrees according to this viewtype. In this viewtype the display of all wg and subphrase nodes are suppresses. The following image shows John 1:1 using this viewtype:
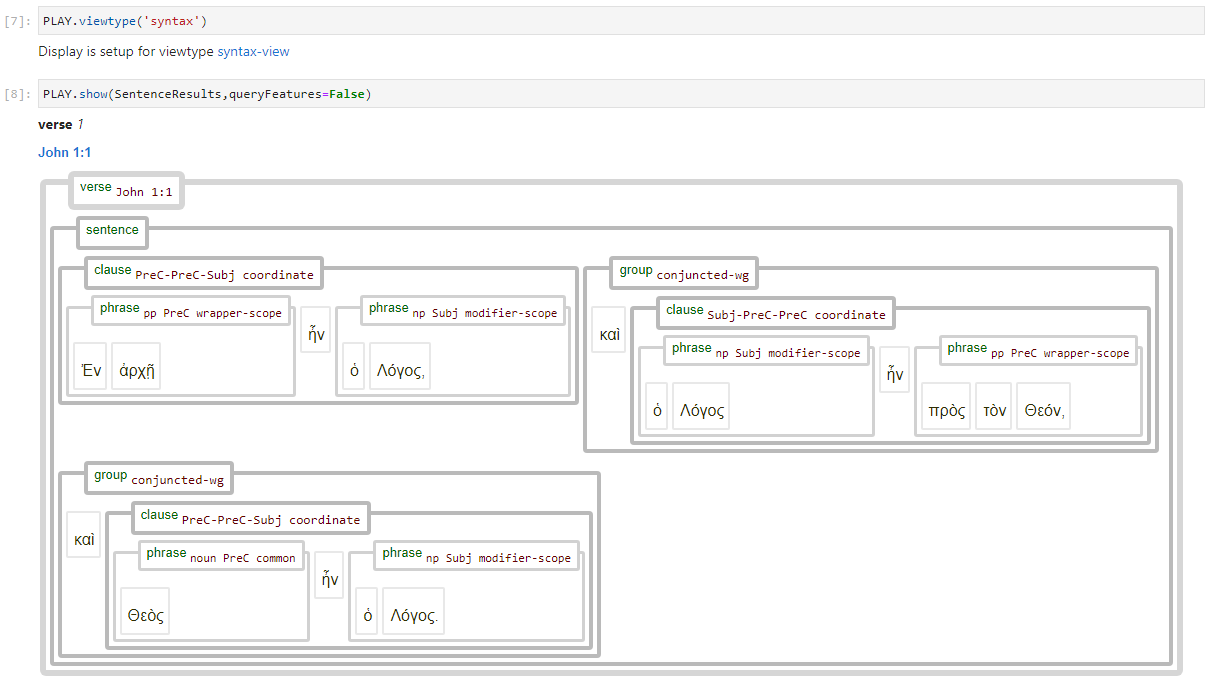
Syntaxtree using the Word-group view
The database also allows for the display of another type of syntax tree, based on the use of word groups instead of clauses and phrases. To switch to this wg-view viewtype, use the command A.viewtype(‘wg’). Selecting this viewtype suppresses the display of all subphrase, phrase, clause and group nodes and changes some of the labels (esp. on sentence nodes). The resulting syntax tree display closely represents the data as found in the XML source files. The following image shows John 1:1 using this view type:
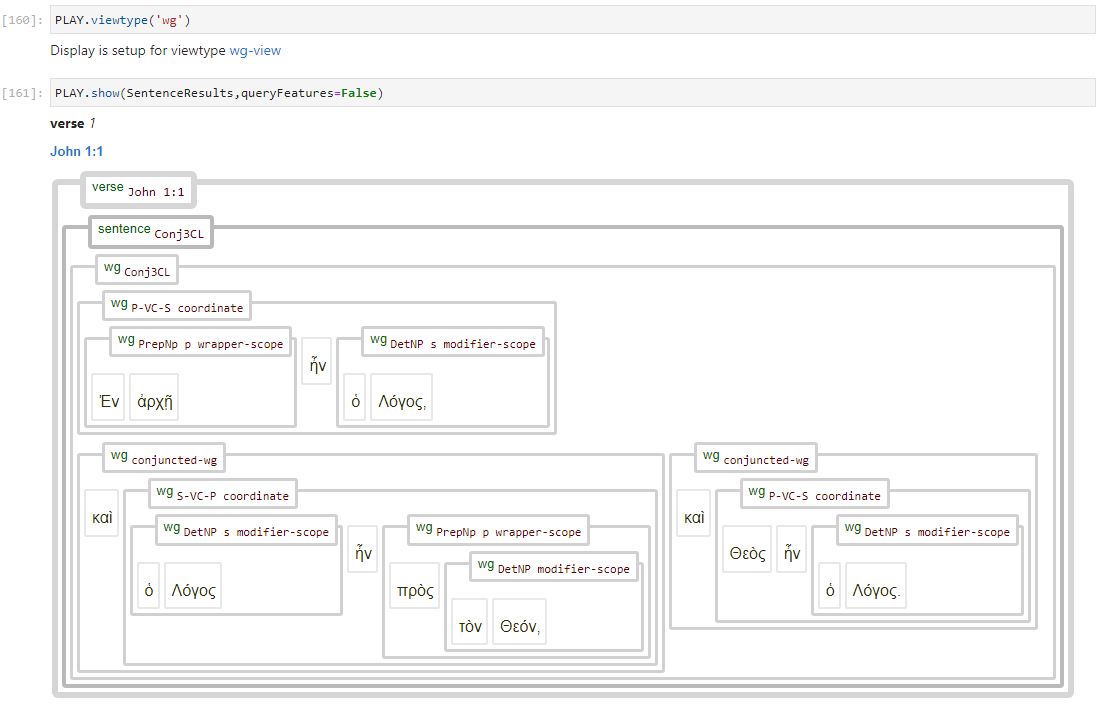
Other implementations
There are various other implementations for syntax trees, each according to their own philosophy. See here for an overview by Jonathan Robie of ‘nine kinds of Ancient Greek Treebanks’ describing various types of syntax-trees with special focus on the Greek New Testament. The following document describes the principles behind syntactic Treebanks for Ancient Greek: Guidelines for the Syntactic Annotation of the Ancient Greek Dependency Treebank (1.1).