N1904-TF
Text-Fabric dataset of the Greek New Testament, based on the Nestle 1904 (7th printing) edition.
About this datasetTranscription
Featureset
Optional features
Viewtypes
Textformats
Syntaxtrees
Tutorial
Latest release
Nestle 1904 GNT - Transcription
This page offers an overview of the transcription of the Nestle 1904 Greek New Testament (GNT) corpus, detailing how the original Greek text was made available as a dataset that can be used in Text-Fabric. It outlines the datasets organisation and provides an overview of the linguistic annotations that are available. More information on the underlying data model is found here.
The Text-Fabric data model
A main design consideration during development of this database was achieving a high level of compatibility with the Bible Online Learner (BibleOL), which utilizes the Nestle 1904 as its base text. This compatibility allowed for including a set of add-on features that can be optionally loaded. A second requirement was that this database should wherever possible mimic the Biblia Hebraica Stuttgartensia Amstelodamensis (BHSA), the ETCBC implementation of the Hebrew Bible, in terms of user experience, nomenclature and data presentation.
Understanding Text-Fabric’s data model is crucial for accurately working with this dataset, particularly when performing linguistic queries. Text-Fabric, true to its name, implements a concepts of ‘warp’ and ‘weft’, inspired by textile weaving, to represent its data. The ‘warp’ denotes the foundational structure, while the ‘weft’ refers to the layers of information, known as features. Part of the structure are the ‘nodes’, each identified by its node type (a string) and a corpus wide unique sequence number (an integer). Associated to these nodes are two feature types: ‘node features’ providing information about individual nodes, and ‘edge features’ describing relationships or links between nodes. These features are then seamlessly woven into the ‘warp’ data, resulting in a strict separation between structure and content. This approach enables Text-Fabric to efficiently handle complex linguistic datasets with versatility.
Slots and tokenization
In Text-Fabric’s data model, slots play a crucial role by defining the positions where the nodes representing the text are stored. The information contained in these slots represents the smallest uniquely addressable linguistic units, often referred to as ‘tokens’. These tokens make the text individually searchable and analyzable. These information stored in these slots can range from individual symbols (e.g., on an Akkadian clay tablets), or individual letters (e.g., from the Dead Sea Scrolls, where the text might lack letters and words, or contain unintelligible parts), to individual words. In this Text-Fabric database, tokenization is based on individual words. Therefore, this database uses ‘word’ nodes to fill these slots, which implies that the smallest linguistic unit that can be queried is a ‘word’. This approach is logical from both exegetical and linguistic perspectives, particularly since the Nestle 1904 corpus is a synthetic text without incomplete or missing words due to damaged manuscripts.
Features
In Text-Fabric, the concept of ‘feature’ refers to the mapping of a node (e.g., the ‘word’ node) to its associated attributes with their values (e.g. for a ‘word’ node: the text itself and other details like grammatical gender). Each node types like ‘word’, ‘wg’ (word groups), ‘sentence’, or ‘verse’ in this dataset has its own set of associated ‘features’ providing additional information specific to that nodetype.
Since this Text-Fabric database contains well over 50 features, four listings are provided, each based on a different types of grouping in order to provide a structured overview:
- Grouped by feature group: e.g.,
Orthographic,Syntactic. - Grouped by node type: e.g.,
word,clause. - Grouped by data type: e.g.,
str,int. The python datatype is relevant when building queries or when processing the data. - Grouped by feature type: e.g.,
node,edge.
Additionally, an alphabetical list of feature names can be found here.
Additional (optional) features
This repository also contains a set approximate fourty additional word node related features covering the following areas:
- Andrews University specific usage of Text-Fabric.
- Aland Synoptics.
- Bible Online Learner related details.
- And a number of other features.
Instructions on how to load these features can be found here.
Views
The concept of viewtypes is important to this dataset. This database offers the users two distinct viewtypes that can be invoked for representing syntax trees:
- syntax-view (default): present syntax trees in linguistic terms like phrases and clauses.
- wg-view: present syntax trees in agnostic terms like word groups.
Textformats
Text-Fabric allows the corpus text to be formatted in different ways, depending on the intended use. This Text-Fabric database has a number of formats defined, which are discussed in the section textformats.
Character encoding
All Greek text in this Text-Fabric dataset is encoded in Unicode. However, there are specific aspects that may require attention when querying, particularly those involving polytonic accents and “pseudo-characters” like the iota subscript. For a detailed discussion on character encoding, please refer to the documentation here.
Implementation notes
General
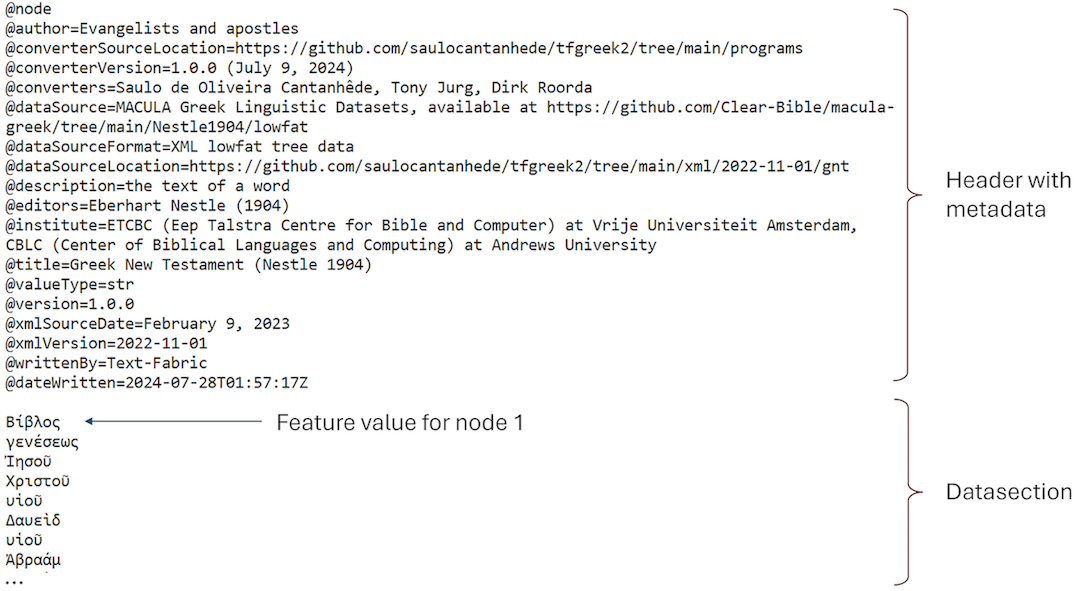
Each Text-Fabric dataset release (version) stores all data related to the corpus base text and its associated features in a single directory ‘/tf/{version}’. The data for each individual feature is stored in plain Unicode text files with the ‘.tf’ extension, with the filename matching the Text-Fabric feature name. These feature files are readable using any ordinary text editor. Each file starts with a header section containing metadata, indicated by lines starting with the ‘@’ symbol, followed by a blank line. This is followed by lines with feature data, where the value stored on a given line ‘n’ is the value of that feature for node ‘n’. Moreover, Text-Fabric uses some data optimizations to handle long sequences of empty lines and long sequences of equal feature values. The following image shows the content of the .tf file for the feature ‘text,’ which is associated with the node type ‘word’:
Mapping of LowFat XML source to TF dataset
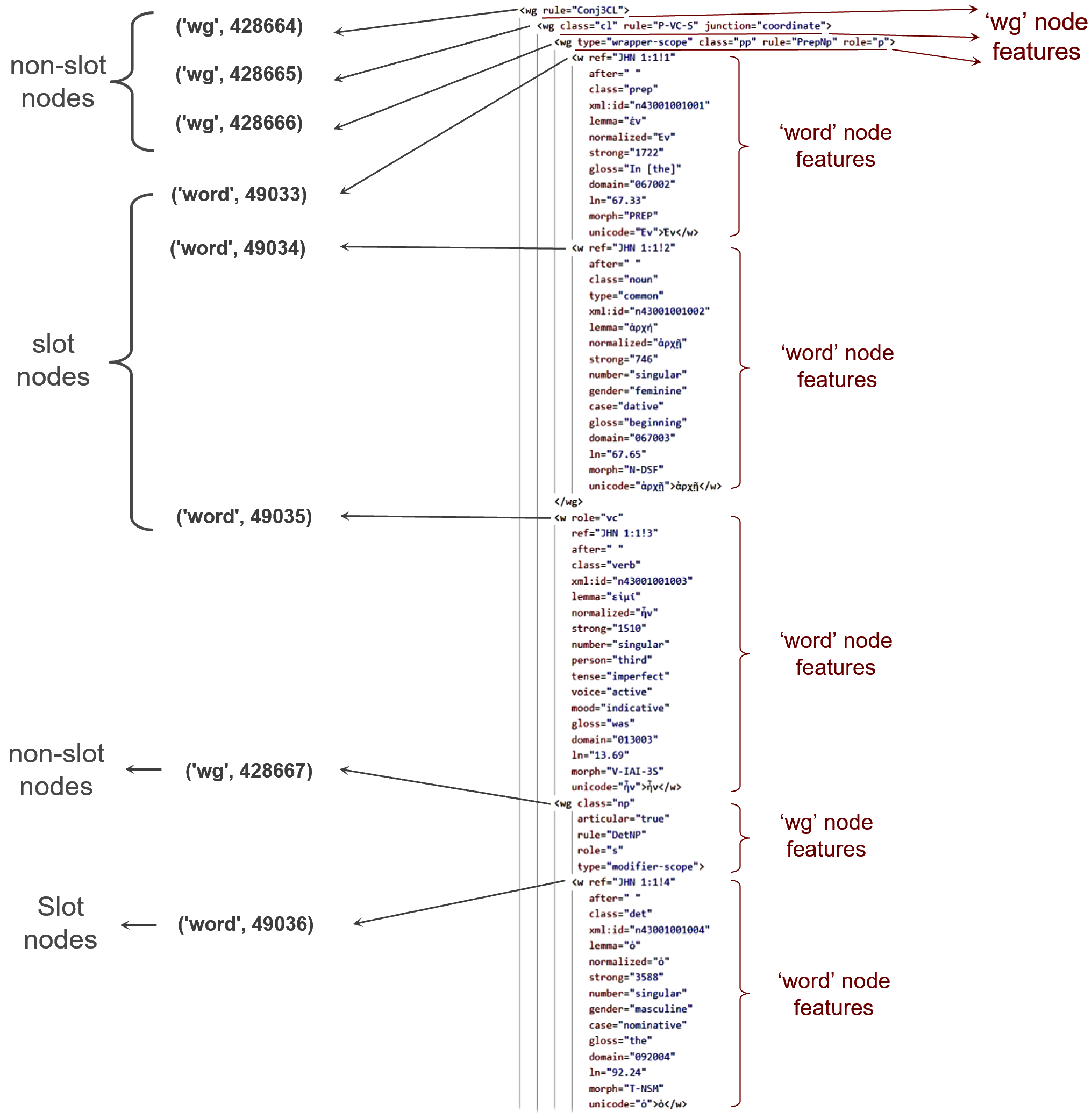
This is a general overview of how the LowFat XML source data maps to Text-Fabrics dataset.
- TF «slot» nodes correspond to the ‘w’ element;
- TF non-«slot» nodes generaly correspond to the *‘wg’ XML elements * or are derived from them;
- TF node type names generaly relate to XML element names (tags);
- TF node features generaly correspond to XML ‘w’ or ‘wg’ element attributes, albeit some with updated values;
- TF edge features correspond to relationships between XLM elements (e.g. parent) or are based on certain XML attributes (eg. frame).
The image below illustrates the basic concept of how LowFat XML maps to TF. For simplicity, the mapping is limited to the TF data used by the wg-viewtype: